My name is Roland Jochems and I have been working in automation for almost 25 years, the last 20 years at CIMSOLUTIONS. During this time I have had to deal with examples of how to use a technique or a service on several occasions and you always get to deal with “hello world” like examples. As friendly as “hello world” sounds, it can be so naive when people decide on the basis of these “hello world” examples whether a technique or service can also be used to solve their own “real world” problems.
I have been working for a while now, for a good customer of CIMSOLUTIONS known for ball bearings, as a systems architect on a system for processing and analyzing data measured on ball bearings of trains. The customer has chosen to use Amazon Web Services for all their customer-facing applications.
AWS
Due to the customer’s choice for AWS, it is up to me to process the data in AWS and IoT. An additional requirement from the customer was to use “serverless”-“managed” services as much as possible, instead of using virtual servers (Ec2) with software running on them. The reason is to keep the costs of managing virtual machines as low as possible. Another reason is that using managed services would be cheaper. I specifically say “would be” because that is not always true and is very dependent on the use of the service.
To get an idea of what kind of application I’m talking about:
Imagine a train where each wheel has a sensor mounted close to the bearing that takes measurements completely independently and uploads data at the time that suits the sensor best.
This train for example has three trainsets each 8 wheels divided over 2 bogies per trainset. That is 24 sensors for that train.
Furthermore, this customer has 16 trains. That amounts to a total of 348 sensors.
These sensors send the data that was measured the day before each day before the service starts again. Which amounts to an average of 285 individual measurements per day per sensor. A total of 348 * 285 ≈ 99,000 records per day for this individual customer. Last January, 2,586 sensors together sent an average of 1,065,866 measurements per day.
Architecture
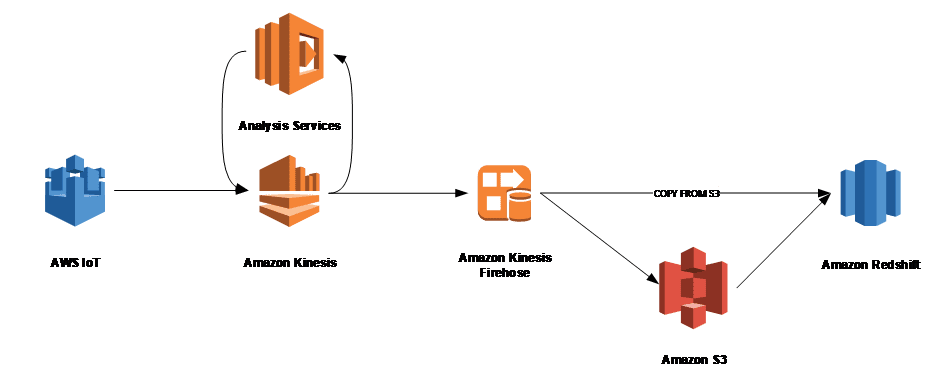
I dove into the AWS literature and went to the Re-Invent conference in Las Vegas to learn a thing or two about AWS and how I can best solve the above use case. Below is a standard architecture as you can find in AWS documentation. I simplified the picture a bit.
We also had the above architecture in mind for processing our sensor data.
Challenge 1: All the “example” and reference applications I have seen so far assume sensors that have a mostly constant connection and then send data when they measure it or send it via an “edge” computing device. This does not cause any problems even with 10k+ sensors, because the distribution of data over the day is fairly evenly spread out. However, as I described in the use case, in our case the bulk of the data can be sent in a relatively short period of time.
Kinesis is a streaming service that regulates the amounts of data by means of chards (literally means shard). Each chard can process 1,000 records or 1MB per second. The number of chards you have available is configurable and has a cost.
A chard is assigned via a key. This way you can guarantee that all data is sent via the same chard and therefore arrives in the same order.
What we quickly ran into is that Kinesis can only process 1,000 records per second and if all sensors of 1 train send data at the same time, we quickly run up against this limit.
Solution 1: Increase the number of chards to handle the peak load. The disadvantage is that after the peak we pay for something we don’t use.
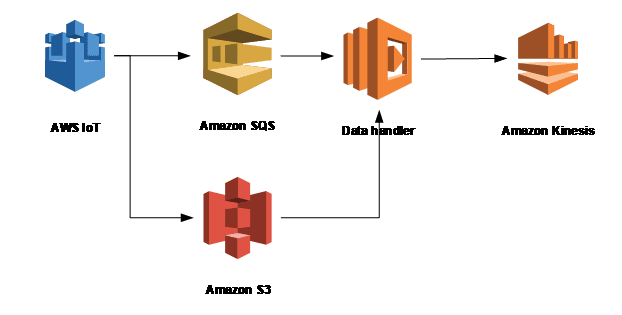
Solution 2: Coping with peak loads using S3 and SQS.
Instead of sending the messages to kinesis at once, they are first written to S3. When the sensor is ready, a message is placed on the queue that the sensor has finished sending and that the data can be processed. The Data Handler reads all the data from that particular sensor and bundles the data to generate fewer messages per second and sends them to kinesis.
S3 and SQS and Lambda are also not without costs, but they still cost less than increasing the chars to handle peak loads.
This project, which is still in full development, has already overcome a number of these hurdles where a proposed technology did not do exactly what you expected.
I will show more of these “hello world vs real world” examples in a future blog.
Roland Jochems
Systems Architect
Also interesting
Blog
From Data to Steering: My journey as a BI Specialist in secondment
How do you translate complex business processes and fragmented data into reliable steering and accountability information that allows an organization to move forward?
From need to realization: why the path to value is rarely linear
By combining design and validation and giving the Business Analyst a directing role before realization, organizations can deliver value faster that truly aligns with operations.
From raw data to business value – Medallion Architecture
The Medallion Architecture, also known as the Multi-Hop Architecture, has received a lot of attention in CIMSOLUTIONS' knowledge-sharing sessions over the past year. This architecture forms the foundation of modern data platforms for a growing number of organizations.
Current AI news is mainly dominated by generative AI and Large Language Models (LLMs). Although these models deliver impressive performance, they also have their limitations.
Quantum computers can perform complex calculations and analyses many times faster and more efficiently than the traditional computers we work with every day.